在写爬虫的时候,为了效率我们通常会选择解析网页api来获取数据,但是有时候解析方式比较困难,或者我们纯粹是为了快速实现爬虫,会使用浏览器自动化操作,说起这一点,肯定第一个想到的就是selenium,但很多时候其实selenium使用起来是不太方便的,例如环境配置,要安装浏览器、下载对应的驱动、安装对应的Python selenium库,而且各个工具的版本还要匹配,大规模部署时就比较麻烦。
下面我们介绍另一个工具-pyppeteer
Pyppeteer简介
pyppeteer是puppeteer的Python版本,而puppeteer是什么呢?puppeteer是Google基于Node.js开发的一个工具,它可以使我们通过JavaScript来控制Chrome浏览器执行一些操作,拥有丰富的API,功能非常强大,因此也可以用于网络爬虫。pyppeteer是一位日本的程序员根据Puppeteer开发的非官方Python版本。
在Pyppeteer中,它操作的是一个类似Chrome的Chromium浏览器,Chromium是相当于Chrome的开发版,是完全开源的,Chrome的所有新功能都会先在Chromium上实现,稳定后才会移植到Chrome上,因此Chromium会包含很多新功能。Pyppeteer就是依赖于Chromium来运行的,当我们第一次运行Pyppeteer的时候,如果Chromium没有安装,那么程序会自动帮我们安装和配置,省去了环境配置这一步。
下面我们详细了解一下Pyppeteer的用法。
安装
因为Pyppeteer采用了async机制,所以必须使用Python 3.5及以上版本。
使用pip安装非常简单:
pip install pyppeteer使用时直接导入:
import pyppeteer使用
接下来我们使用豆瓣电影排行榜https://movie.douban.com/chart来作为测试

下面我们用Pyppeteer来试一下,代码如下:
import asyncio
from pyppeteer import launch
from lxml import etree
async def main():
browser = await launch()
page = await browser.newPage()
await page.goto(\'https://movie.douban.com/chart\')
await page.waitForXPath(\'//table//a[@title]\')
doc = etree.HTML(await page.content())
names = [element.attrib[\'title\'] for element in doc.xpath(\'//table//a[@title]\')]
print(\'Names: \', names)
await browser.close()
asyncio.get_event_loop().run_until_complete(main())运行结果:
Names: [\'誓血五人组\', \'给我翅膀\', \'黑帮大佬和我的365日\', \'爱情人偶\', \'忠贞\', \'鲁邦三世 The First\', \'大饿\', \'火口的两人\', \'知晓天空之蓝的人啊\', \'野性的呼唤\']代码的大体意思是访问网站,然后等待//table//a[@title]的节点加载出来,再通过xpath从网页源码中解析出电影名并输出,最后关闭Pyppeteer。具体过程如下:
- launch 方法新建一个Browser对象,赋值给browser变量,这一步就相当于启动了浏览器
- 然后browser调用newPage方法相当于新建一个选项卡,并且返回一个Page对象,这一步还是一个空白的页面,并未访问任何页面
- 然后Page调用goto方法,就相当于访问此页面
- Page对象调用waitForXpath方法,那么页面就会等待选择器所对应的节点信息加载出来,如果加载出来就立即返回,否则就会持续等待直到超时。这里就比selenium的等待元素加载完毕要清晰的多了。
- 页面加载完成后再调用content方法,获取渲染出来的页面源代码
- 最后从页面源码中提取出电影名称
另外当中还用到了asyncio的相关知识,因为Pyppeteer是基于asyncio实现的异步,所以这块知识需要先了解一下。
通过上面这个示例,我们看到Pyppeteer比Selenium要简洁的多,而且环境配置也方便,直接自动帮我们实现了环境配置。接下来我们再尝试设定浏览器窗口大小,并进行网页截图,然后执行一段自定义的JavaScript脚本,代码如下:
import asyncio
from pyppeteer import launch
async def main():
width, height = 1366, 768
browser = await launch()
page = await browser.newPage()
await page.setViewport({\'width\': width, \'height\': height})
await page.goto(\'https://movie.douban.com/chart\')
await page.waitForXPath(\'//table//a[@title]\')
await asyncio.sleep(2)
await page.screenshot(path=\'example.png\')
dimensions = await page.evaluate(\'\'\'() => {
return {
width: document.documentElement.clientWidth,
height: document.documentElement.clientHeight,
deviceScaleFactor: window.devicePixelRatio,
}
}\'\'\')
print(dimensions)
await browser.close()
asyncio.get_event_loop().run_until_complete(main())执行结果:
{\'width\': 1366, \'height\': 768, \'deviceScaleFactor\': 1}这里我们完成了页面窗口大小的设置、网页截图保存、执行了JavaScript并返回了对应的数据。图片如下:
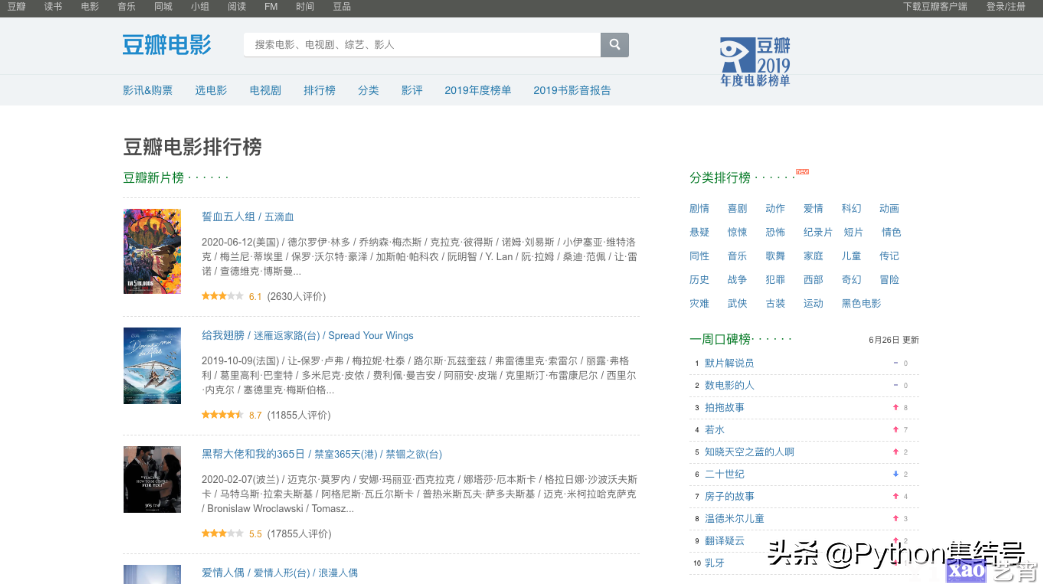
我们这里是全屏截图,screenshot方法还可以指定保存格式、清晰度、是否全屏、裁剪等。从截图我们可以看到和我们在浏览器中看到的一样,并且在evaluate方法中执行的JavaScript返回了网页的宽高、像素大小比率的值。
今天我们简单介绍Pyppeteer的使用,更加详细的介绍可以在Pyppeteer的官方文档https://miyakogi.github.io/pyppeteer/reference.html中进行查找,不必死记硬背。下一篇我们介绍一些常用的Pyppeteer对象和使用模式。
内容出处:,
声明:本网站所收集的部分公开资料来源于互联网,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,也不构成任何其他建议。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。文章链接:http://www.yixao.com/share/13187.html
 微信扫一扫
微信扫一扫
 支付宝扫一扫
支付宝扫一扫
相关推荐
-
PrimeVue:一个号称最完整的Vue UI组件库的Vue组件框架
PrimeVue是一个为数不多的高质量Vue组件库,同时支持Vue2 和 Vue3,像Antd、Element UI以及naive-ui等都是比较不错的组件,PrimeVue相较而言是比较陌生的一个,也算是对这一类生态的一个补充,可以作为一个不错的选择!
-
Mall:用SpringBoot实现一个电商系统
目前最为主流的 Web 开发技术,包括 SpringBoot、MyBatis、MongoDB、Kibina、Docker、Vue 等,都是开发者十分需要掌握的技术。有没有一个全面而…
-
php开发的简单轻量级的web防火墙,拦截SQL注入和XSS攻击
一个朋友发给我看的小的web防火墙,是基于php开发的,整体就一个文件,比较简单,能拦截一些SQL注入和XSS攻击,整个代码也是100多行,主要就是利用一些正则匹配拦截。还支持自定…
-
谷歌Chrome 69浏览器正式版发布 全新视觉UI、搜索/密码管理更强大
正如此前预告,作为Chrome十周年活动的一部分,Chrome 69即日起(9月5日)在全平台发布,包括但不限于Windows、Android、iOS等。 Chrome 69在UI…
-
Gpluscard虚拟信用卡申请与充值教程
之前小编就有给大家分享过虚拟信用卡的申请教程,今天呢给大家带来一个新的虚拟卡的申请方式。Gpluscard是最近新推出的一种虚拟卡,属于visa卡,目前正在推广期,不仅免费开卡,新…
-
《胡闹厨房2》Epic限时免费
Epic又送好东东了,《胡闹厨房2》一键领取入库。 领取地址:https://www.epicgames.com/store/zh-CN/p/overcooked-2 《胡闹厨房2…
-
Compressor–JavaScript压缩图片的国产类库
简要介绍 Compressor.js是一款压缩图片的JavaScript组件。它在github上有2.7k颗星,可以用于图片上传时对图片进行压缩。值得一提的是,该作品是正宗的国货,…
-
短网址生成接口最新官方api分享
简要描述 短网址,顾名思义就是一种较短域名加动态参数组成的短地址,类似于t.cn/xxxx,url.cn/xxx。是由各大平台诸如新浪、腾讯、百度发布的短网址接口将长网址转换而来的…
-
MyBatis插件介绍
1. 前言 MyBatis 允许我们以插件的形式对已映射语句执行过程中的某一点进行拦截调用,通俗一点来说,MyBatis 的插件其实更应该被称作为拦截器。 MyBatis 插件的使…
-
2020年排名前10的Flutter和React Native UI库
Flutter 如今,Flutter在移动技术中扮演着非常重要的角色。移动技术的选择已经变得非常关键,Flutter提高了生产率,Flutter已被许多公司采用。一些例子如阿里巴巴…