在我们上线运行Doris时,又发现RapidsDB这款MPP数据库非常优秀,号称能支持TB级数据在毫秒内响应(处理千亿的数据在毫秒内响应)。可以预见,随着数据库技术的不断进步,可以大大提高OLAP的数据分析能力。
一 开发背景
从2018年开始,新浪微博使用Kylin做OLAP数据分析,但是Kylin只能用来做固化的OLAP数据分析,固化的多维分析,就需要提前定义好指标和维度,同时Kylin又有维度爆炸的风险。这样,就不能随意添加条件或者关联表进行灵活的数据分析查询。
还有一个更严重的问题,Kylin中都是聚合后的数据,没有保留明细数据,在查询问题的时候,没有办法进行下钻分析。
二 面临的痛点
2.1 汇总数据的交互式查询
数据分析师团队最典型的应用场景就是,在各种维度下进行自定义查询,面对如此灵活多变、多见即所得的应用场景,既有的Kylin系统是没办法支持的。我们没办法把所有的场景都能预想出来。Kylin是一种预计算的执行引擎,比如我们想计算过去3个月微博,在每个渠道的展现情况,需要重新计算3个月的Cube,要花费几个小时的时间。
2.2 明细数据的交互式查询
除了要分析汇总数据之外,对明细数据的查询也是一种刚需。通常会选择MySQL这种关系型数据库作为明细数据的快速检索,但是如果数据量非常大,MySQL显然是不能够支持的,并且如果遇到大量数据同步、新增字段和历史数据变更的时候,运维成本都非常高。
2.3 生产环境面临的挑战
数据呈爆炸模式增长,每天都需要用新的维度对历史数据进行回溯。在使用Kylin计算时,会有如下问题:
- 每天都要回溯历史数据,就失去了增量计算的意义。
- 每天要回溯历史数据量非常大,大概有10亿+的历史数据需要回溯。
- 数据计算耗时4个多小时,存储2TB+,消耗大量计算存储资源。
- 不支持明细数据的查询。
2.4 解决方案:引入MPP引擎,数据现用现算
随着分布式、并行化技术成熟应用,MPP引擎逐渐表现出强大的高吞吐、低时延计算能力,号称“亿级秒开”的引擎不在少数,单从业务实际应用考虑,性能在千万量级关联查询现场计算秒开的情况下,已经可以覆盖到很多应用场景,具备应用的可能性。
2.5 MPP引擎的选型
开源并且熟知的OLAP引擎有很多,比如Greenplum、Apache Impala、Presto、Doris、ClickHouse、Druid、TiDB等,我们结合自身业务的需求,从引擎建设成本出发,并立足于公司技术生态融合、集成、易用性等维度进行综合考虑,我们最终选择了Apache社区的Doris。

三 Apache Doris介绍
Doris是一种MPP架构的OLAP执行引擎,主要整合了Google Mesa(数据模型)、Apache Impala(MPP Query Engine)和Apache ORCFile (存储格式,编码和压缩)的技术。
3.1 Doris的架构
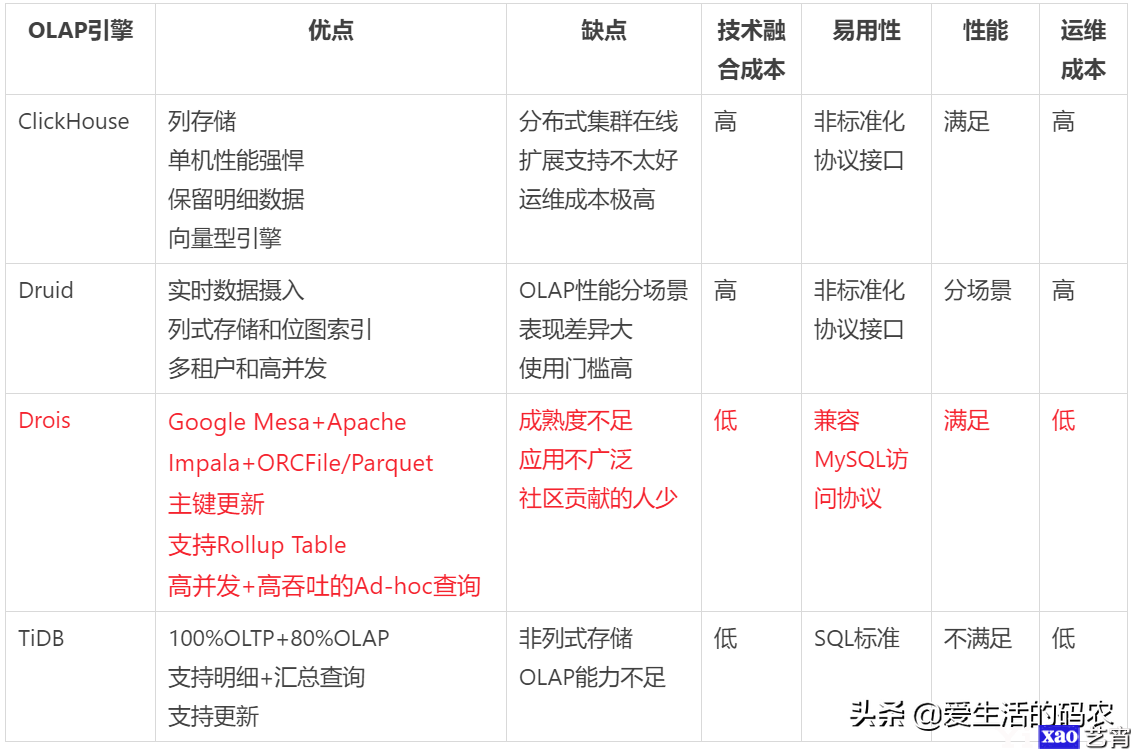
Doris的架构和TiDB类似,借助MySQL的协议,用户可以使用任意MySQL的ODBC/JDBC以及MySQL客户端,都可以直接访问Doris。Doris中的模块主要包括FE和BE两类:FE主要负责元数据的管理、存储,以及查询解析等;BE节点主要负责数据的存储、以及查询计划执行。
一个用户的SQL请求,经过FE解析、规划后,将具体的执行计划发送给BE,BE完成具体的查询任务。
FE的主要代码都是由Java开发,而BE的底层代码是由C++开发的。
3.2 Doris的数据分布
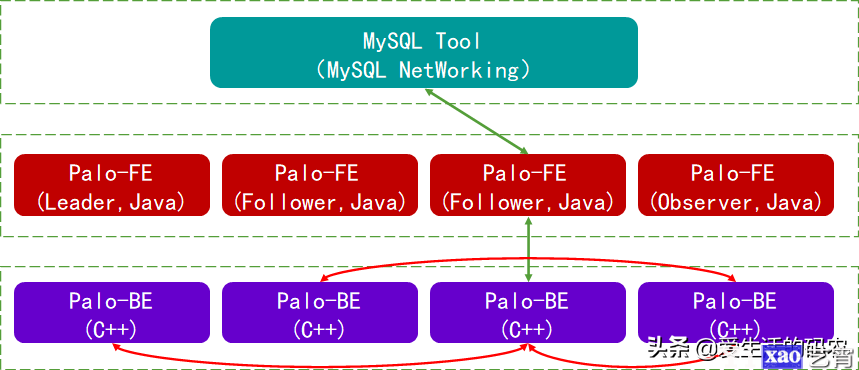
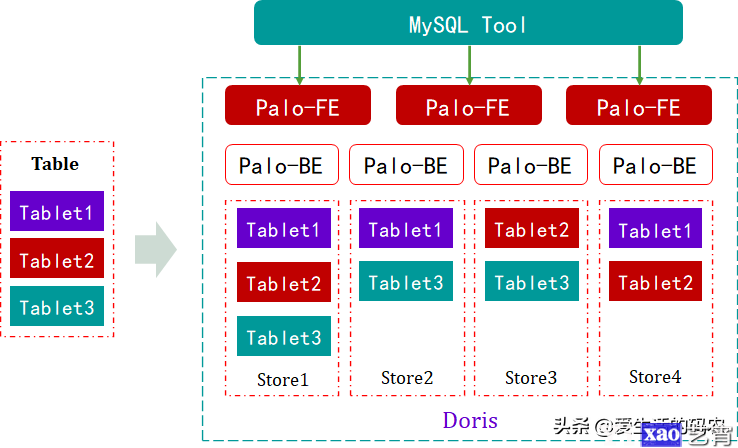
如果从Table的角度看数据结构,用户的一张Table会拆分成多个Tablet,Tablet会生成副本,存储在不同的BE中,从而保证数据的高可用和高可靠性。
3.3 易运维
Doris 部署无外部依赖,只需要部署 BE 和 BE,即可搭建起一个集群。
支持 Online Schema Change:支持在线更改表模式 ( 加减列,创建 Rollup ),不会影响当前服务,不会阻塞读、写等操作;这种执行是异步的 ( 用户不需要一直盯在那里 )。
3.4 Doris的特点总结
- 同时支持高并发点查询和高吞吐的Ad-hoc查询。
- 同时支持离线批量导入和实时数据导入。
- 同时支持明细和聚合查询。
- 兼容MySQL协议和标准SQL。
- 支持Rollup Table和Rollup Table的智能查询路由。
- 支持较好的多表Join策略和灵活的表达式查询。
- 支持Schema在线变更。
- 支持Range和Hash二级分区。
四 采用Doris做OLAP引擎
新浪微博采用30台BE+5FE的Doris环境,效率、性能表现情况如下:
- 支持30+个数据分析产品类型以上,整体响应速度达到ms级。
- 支持百万、千万级大表关联查询,同时进行维表关联的雪花模型,经过Colocate Join特性优化,可以实现秒级响应。
- 日级别,基于渠道、微博类型,同时满足汇总及下钻明细查询,都可以在秒级别查询出数据。
- 7日数据趋势分析查询,需要2~3秒。在数据量较大时,需要调动很多的集群资源,因此MPP的并发性能受限于集群的性能。
- 通过3年多的应用以及Doris的不断改进升级,Doris的高可靠、高可用、高可扩展性也得到进一步验证。
4.1 Colocate Join
Colocate Join(Local Join)是和Shuffle Join、Broadcast Join相对的概念,即将两表的数据提前按照Join Key Shard,这样在Join执行时就没有数据网络传输的开销,两表可以直接在本地进行Join。
整个Colocate Join在Doris中实现的关键点如下:
- 数据导入时保证数据本地性。
- 查询调度时保证数据本地性。
- 数据Balance后保证数据本地性。
4.2 Bitmap 精确去重
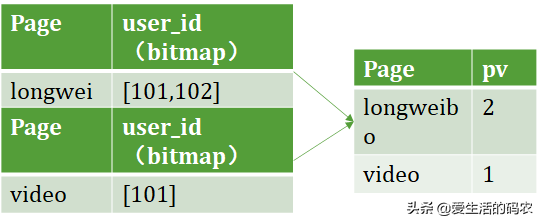
当数据量越来越大,到几十亿几百亿时,使用的IO资源、CPU资源、内存资源、网络资源会变得越来越多,查询也会变得越来越慢。
于是我们在Doris中新增了一种Bitmap聚合指标,数据导入时,相同维度列的数据会使用Bitmap聚合。有了Bitmap后,Doris中计算精确去重的方式如下:
五 经验总结
在平台同学的共同努力下,Doris引擎性能还有较大提升空间,相信以Doris引擎为驱动的ROLAP模式会为微博的业务团队带来更大的收益。
在我们上线运行Doris时,又发现RapidsDB这款MPP数据库非常优秀,号称能支持TB级数据在毫秒内响应(处理千亿的数据在毫秒内响应)。可以预见,随着数据库技术的不断进步,可以大大提高OLAP的数据分析能力。
内容出处:,
声明:本网站所收集的部分公开资料来源于互联网,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,也不构成任何其他建议。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。文章链接:http://www.yixao.com/tech/26025.html
 微信扫一扫
微信扫一扫
 支付宝扫一扫
支付宝扫一扫
相关推荐
-
揭秘互联网黑灰产业链 带你走进埋藏在最深处的地下江湖
带你走进埋藏在互联网最深处的地下产业江湖。1.刷单广告公司付款请人假扮顾客,用以假乱真的消费方式提高产品的销量获取好评吸引顾客。分为机器刷、人刷。机器刷指利用群控等设备统一的大量刷…
-
为什么要用HTTPS?因为HTTP不安全
近几年,互联网发生着翻天覆地的变化,尤其是我们一直习以为常的 HTTP 协议在逐渐的被 HTTPS 协议所取代,那么,为什么要用 HTTPS?因为 HTTP 不安全! HTTP 协…
-
腾讯IMWeb前端团队解读2020年七大前端技术趋势
时光荏苒,非比寻常的一年即将过去。在这过去的一年中,与其说前端的平稳期即将到来,不如说前端反而进入了技术深水区。换言之,在全栈和多端的影响下,前端领域里“术业有专攻”的时代已经到来…
-
K8S云平台部署过程说明
近期由于工作原因,在项目支持的过程中,进行了一次K8S的基础环境部署,云平台一直是公司的重要底座,而我由于一系列原因,一直没有亲自尝试,通过本次的机会,让我重新做了一遍,也找到了和…
-
WiFi爆出重大安全漏洞,WPA2加密协议已被攻破
据研究机构周一发表的研究报告,用于保护Wi-Fi网络安全的保护机制已被黑客攻破,使他们可能监听到通过接入网络的设备进行的通讯交流。 WPA2是用于保护现代Wi-Fi网络的安全协议。…
-
只需三步即可使用SDK玩转阿里云API
众所周知,阿里云提供了全方位、多层次的云计算产品体系。阿里巴巴技术委员会主席王坚博士说过,要让云计算像水电一样方便获得。为了开发者无缝衔接阿里云的众多服务,将它们集成到自己的应用系…
-
Let’s Encrypt 将于2018年1月起提供免费泛域名SSL证书
今天的一个好新闻, Let\’s Encrypt 将于2018年 1 月起提供免费泛域名SSL证书,也就是我们俗称的野卡(Wildcard)。 新闻地址:https:/…
-
把搜索神器「Everything」整合到 Windows10
说到文件搜索功能,虽然 Windows 10 自带的搜索已经改善不少了,之前卡机械硬盘,索引慢的情况在新版本里面都有所改善,不过还是满足不了经常用到搜索功能的用户。 搜索软件想必大…
-
利用搜狐快站建设网站,草根站长的首选
对于搜狐快站,下面就进入今天的主题,给大家一步一步的讲解,菜鸟一看就会。 第一,注册搜狐快站到建站页面的几个步骤 1,打开搜狐快站官方网站,点击右上角的注册 2,填写资料上的邮箱,…
-
Service Mesh架构下的认证与授权
我们需要一个用户池来管理用户,但我们不想在用户的账号密码等逻辑上花费太多精力,因此决定使用微信作为我们的用户池,用户进入我们的系统时,使用微信登录即可,这样就可以将“创建新用户”,“修改密码”,“找回密码”和“短信验证码”等逻辑委托给微信,同时也免去了用户进入系统时的“注册”过程,一举两得。