MangaDex(managdex.org是个漫画网站,Alexa世界排名约6k名)
MangaDex v3 有时在全球最受欢迎的 1000 个网站中名列前茅。而 v5,虽然仍处于公测阶段,缺少许多功能和润色,但已经在前 10 000 名中回升了不少。
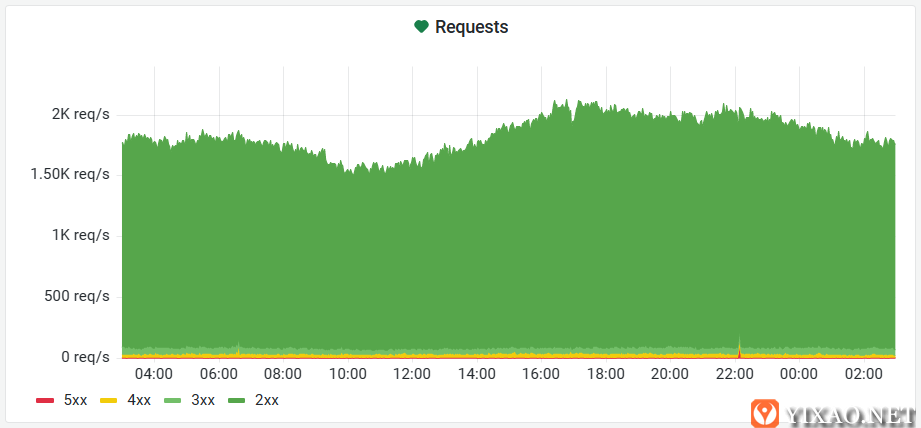

24 小时内每秒请求数- 计算方式为 30 秒滑动窗口的速率
目前在黄金时段看到每秒超过 2000 个请求的峰值。这是每月数十亿的请求,或超过1000 万的每月独立访问者。
相比之下,每月约 1500 美元的预算会让许多运行类似规模平台的人笑着离开房间,认为您肯定忘记了少加一些零。因此,MangaDex 偶然地超越了“正常工作”的地步,需要创造力、研究和实验的结合才能保持活力,尤其是保持增长。
这是一个由扫描社区驱动并为扫描社区服务的平台,任何人都可以在该平台上免费、无广告地阅读漫画,并且绝对不用担心图像质量。
介绍
MangaDex v3 继续在线服务并且经历了最痛苦的结局,因此v5 重建的主要目标之一是确保将来能够以安全和高性能的方式运营该平台。
那么,我们所说的“基础设施”指的是什么?
基础设施,名词
系统或组织的底层基础或基本框架 […]
~ Merriam Webster 字典
嗯,这仍然很模糊。在这里,它将被用来表示我们的应用程序所在的基础。
更具体地说:让数据库随时可用、监控和备份以供后端使用将是基础设施工作。
我们去哪?
在长期开展复杂项目时,牢记最终目标。它可能很遥远,可能不得不在通往它的路上走一些意想不到的弯路,但在做出重要的架构决策时,它是一个很好的指南,朝着它迈出的每一步都是胜利。
以下按此顺序是基础设施最重要的特性:设计的安全性、可观察性、可靠性和可扩展性。
有了这个,讨论当前系统的这些方面。
当前状态概述和限制
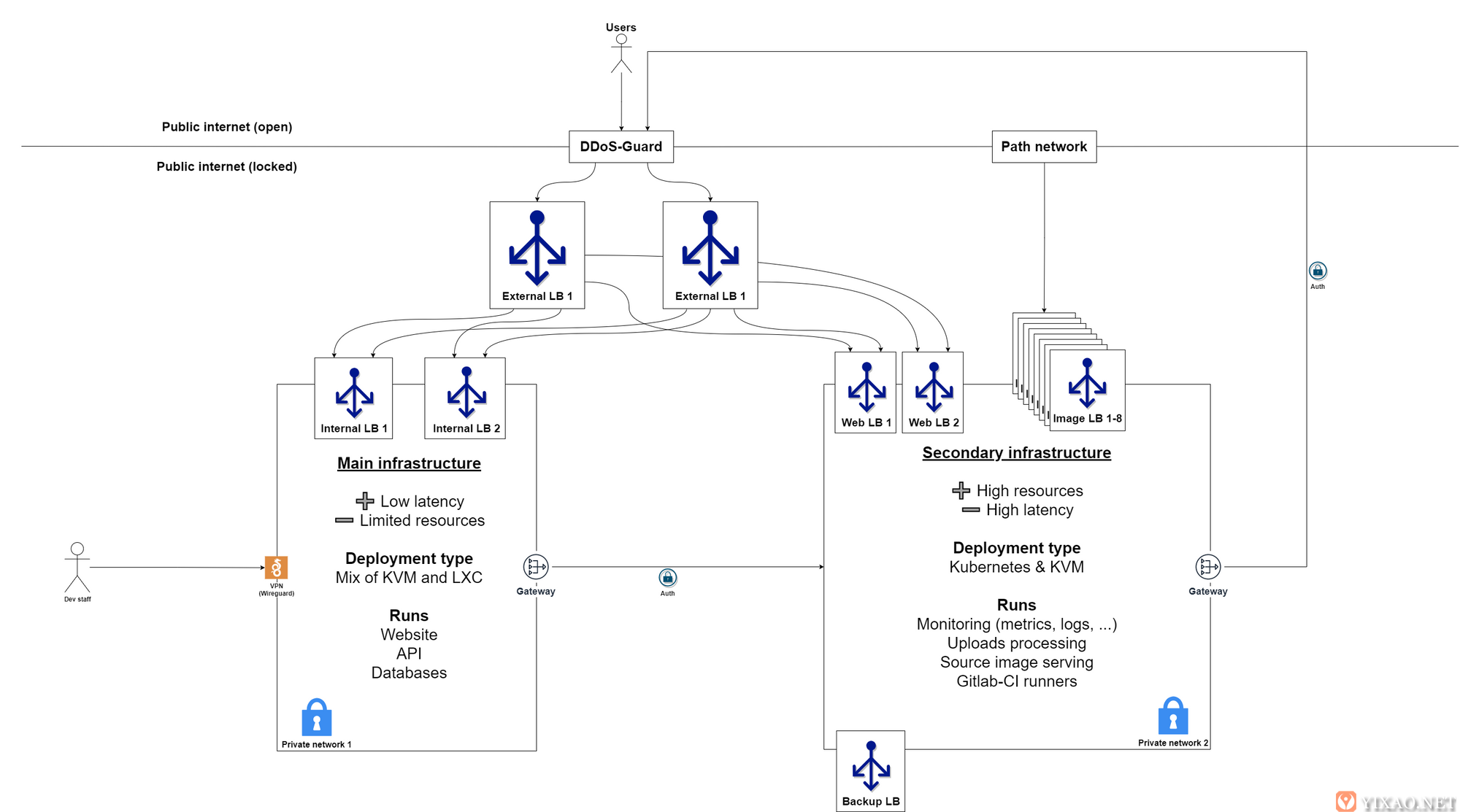
生产网络图的简化概述
这是当前生产网络的视图。两个主要中心的分裂是因为有可以在两个不同地理区域访问的基础设施,但真的负担不起对服务器所在位置的要求。我们在力所能及的范围内进行良好的部署并充分利用它。

主要部署的概述
这本质上是网络图中左侧框的放大图。对生产 VPN 的访问也只授予那些积极需要它的人。添加 NAT 网关可确保如果公共 IP 通过某种类似 SSRF 的攻击以某种方式泄漏,我们只需要交换一个地址即可影响所有主机。并且为了避免误解,没有使用 AWS S3 作为对象存储,这太昂贵了。但是,确实使用商业对象存储服务,因为我仍然希望备份的安全性具有绝对的确定性。
开发环境2本质上是一个较小规模的副本(两个后端而不是三个 – 两个 Elasticsearch 数据承载节点而不是三个 – 并且通常更小)。它确实将其指标/日志推送到与生产服务器相同的监控基础设施,但在其他方面完全不相关(不同的提供商、网络、数据库……)。虽然让它与环境1足够相似成本有点昂贵,但它在必要时进行大量配置更改。唯一缺少的一点是复制生产流量的能力,因为一些错误仅在大量并发用户的高流量下才会发生。然而,这充其量是很难或几乎不可能做到的。
当前部署方案的一个主要缺点是 DDoS-Guard 的区域间性能(非常)差。再加上由于物理上远离服务器(尤其是在亚洲)而延迟会自然增加,这导致欧洲以外的最终用户体验非常差。
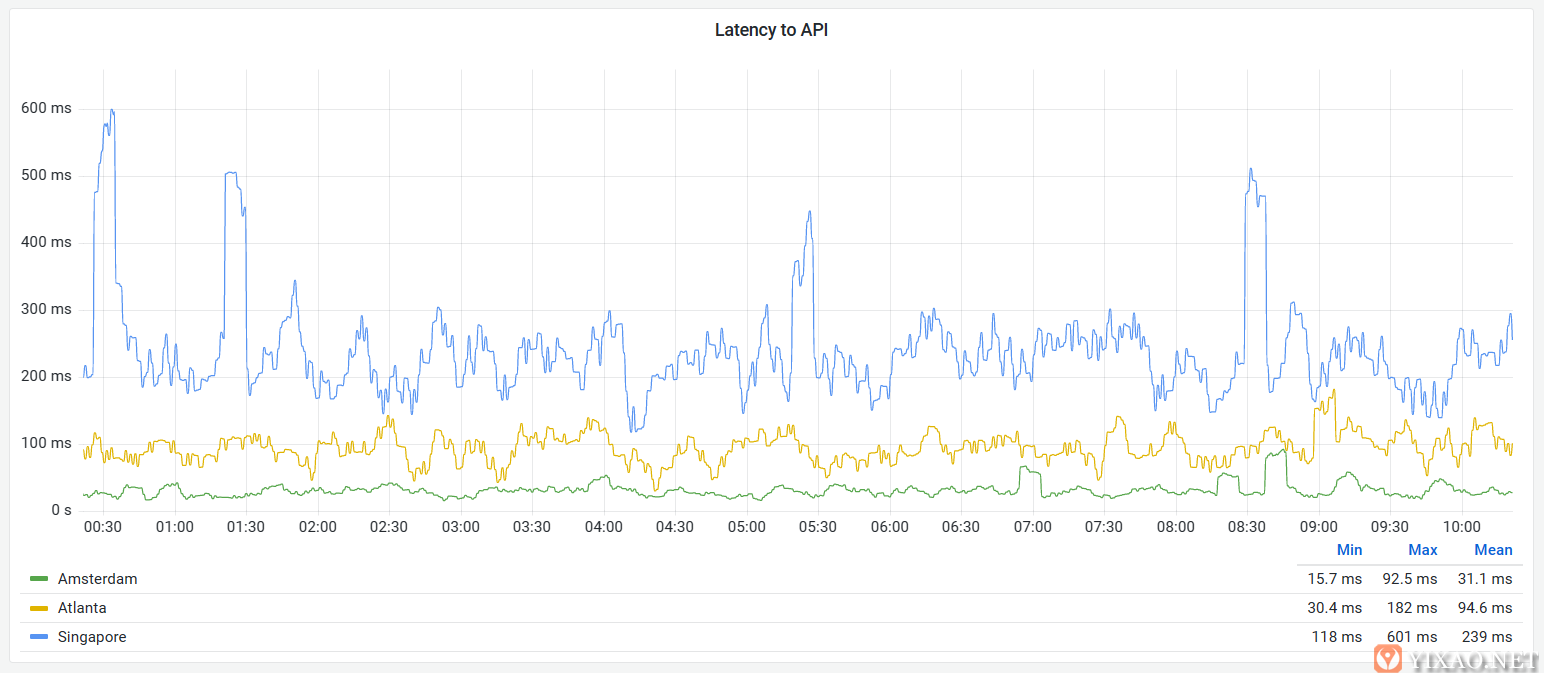
世界各地多个城市的 API 的有效延迟
持续监控世界上多个主要城市的站点的可访问性和响应性,并以欧洲为基准,观察到北美用户延迟的三倍到亚洲延迟的近十倍,有一些明显的峰值或直线上升不可达。
已计划对此进行补救,但这并非易事。这个想法是拥有区域本地只读镜像,并使用Consul或Istio之一在区域间级别将其全部连接起来,以在全球范围内建立安全、离散的服务网格,并且仍然防止任何横向移动能力到潜在的入侵者。像 Varnish + Backend + MySQL/ES 只读副本这样的东西将大大加快远程用户的访问速度。
目前尚不清楚其中哪些最适合用于目的。由于已经使用了几个 HashiCorp 产品(Terraform用于开发环境配置和Vault用于一般的机密管理),如果 Consul 能做到这一点并且可以利用它们的集成,那就太好了。
然而,当从更多点对点类型的系统中受益时,Consul 似乎更多地假设了一个“中心”模型。有一些方法可以解决这个问题,特别是使用像Kilo这样的CNI为每个区域形成一个 Kubernetes 集群,它通过 Wireguard 隧道建立对等网络。
要使最后一点成为现实,仍然需要进行很多测试,但希望它不会太远。
部署概述
目前,部署环境有两种类型:裸虚拟机和 Kubernetes 集群。
VM 通常基于KVM或LXC。经验法则是,如果它位于公开网络环境,将使用 KVM,否则尽可能使用 LXC,它稍微灵活一些(但由于与主机的非完全隔离而有一些缺点,例如一些共享的 sysctls 值) . VM 使用出色的Proxmox进行管理,然后使用Ansible进行配置。
我们(有些不情愿地)默认使用Ubuntu Server 20.04,因为 CentOS 7 开始严重陈旧,而 CentOS 8 在这一点上基本上是死胎。特别是,我们正在密切关注Rocky Linux和Alma Linux,因为它们都旨在成为 CentOS 的精神继承者,并有望在未来成为强大的操作系统选择,一旦它们获得更多牵引力并经过一些实战测试我们的工具。
对于Kubernetes集群,使用Ansible,特别是Kubespray项目的剧本,这有助于避免Kubernetes的大多数偶尔荒谬的默认设置(例如,标准的 CoreDNS-only 部署仍然只是一个非常糟糕的笑话,强烈建议您查看到任何操作它的节点本地 DNS 缓存中),并且通常使内部部署集群的管理成为一种愉快的体验。
监控概览
熟悉它的人会在本文分享的屏幕截图中认出出色的Grafana(这里偏爱它的浅色主题)。
有两种主要类型的监控数据可供使用:指标和日志。这些有大量的 SaaS 选项,所有这些都太贵了,所以我们也在内部运行它们。这并不理想,因为它开启了我们的监控与我们的环境之一一起关闭的可能性,但资金毕竟不会长在树上。
话虽如此,我们通过在每个主机3上运行一个最小的Prometheus实例来收集指标,禁用持久性并配置为使用远程写入功能将指标持续发送到集中的Cortex实例。
至于日志,使用Promtail将它们发送到一个集中的Loki实例。
然后我们依靠Ceph的对象网关(有时称为 Rados 网关)来持久存储这些数据。将所有这些联系在一起的模板如下所示:

Cephs
Ceph可能是过去几年使用过的最令人印象深刻的存储技术之一。它绝对可以满足几乎所有类型的存储需求,并为网络附加存储系统提供一些不真实的性能。此外,它可以被消耗:
- 作为内核级别的块设备(不需要 FUSE )
- 作为共享文件系统(考虑 NFS 但速度快且接近 POSIX语义)
- 作为S3 兼容的API
我们在不同的地方广泛使用了所有这些,稍后它真的值得自己写一篇文章。就目前而言,很容易理解为什么它是CERN和许多科技巨头使用的主要存储技术之一。
稍后会详细介绍,但这里强烈推荐它用于横向扩展存储目的。此外,Proxmox 为在服务器集群上部署和管理它提供了出色的原生支持,而Rook 有一个很好的操作器,可以在 Kubernetes 节点存储或 PVC 上运行它。
指标
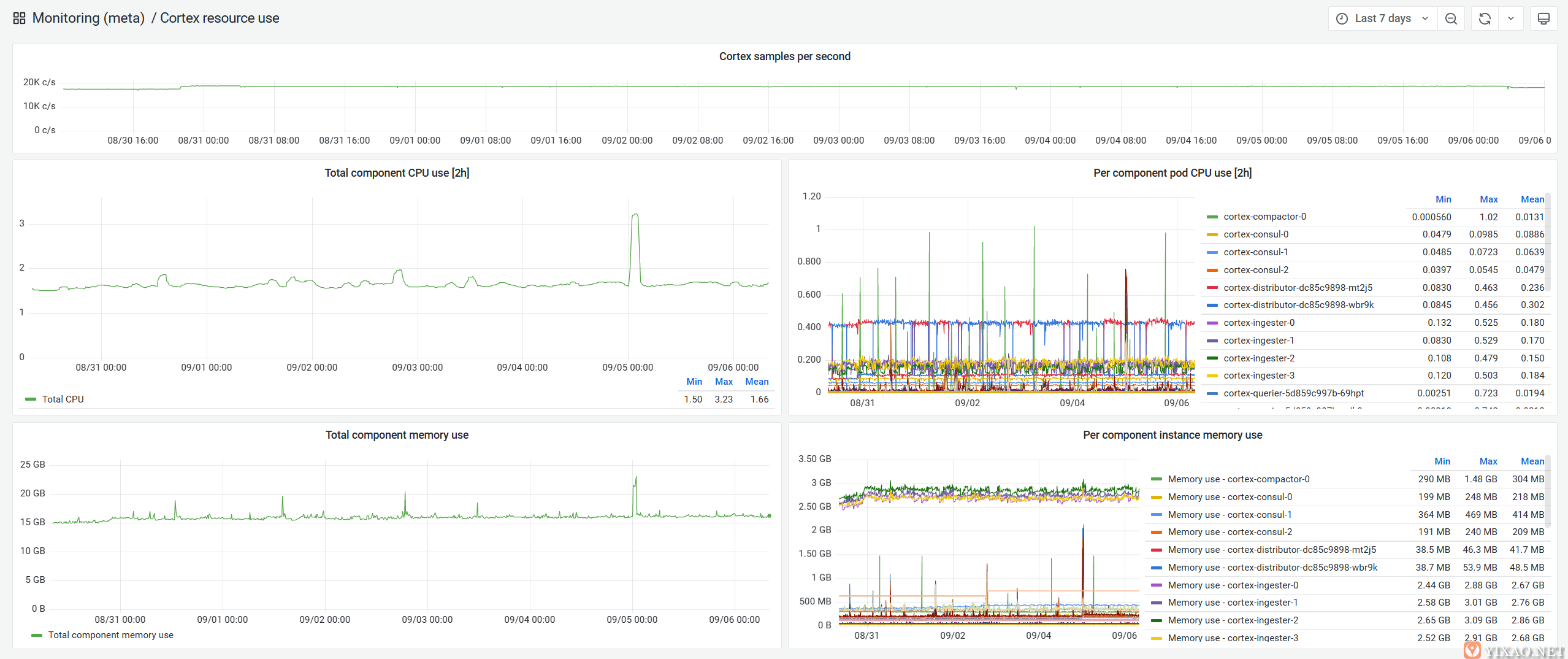
如上所述,在我们管理的每台主机上收集指标,并将它们发送到中央Cortex集群,该集群本身部署在 Kubernetes 中。它充当水平可扩展且速度极快的 Prometheus 兼容系统,用于长期存储和查询指标。
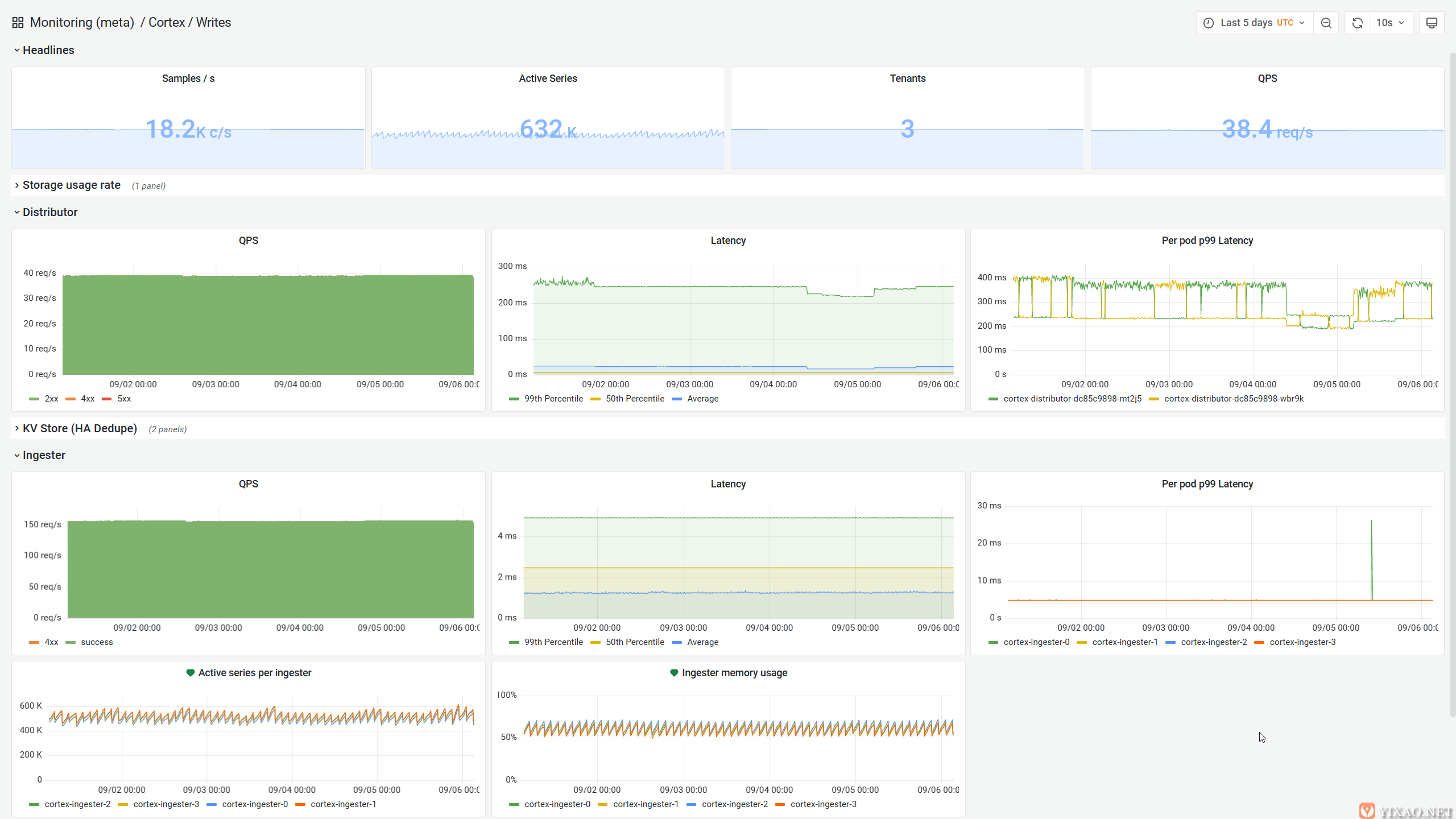
Cortex 指标摄取监控
它恰好也支持多租户,这意味着我们可以安全地将它用于公共MangaDex@Home仪表板。
它利用多级缓存(内存中 tsdb 头、内存中结果缓存和内存缓存)在长时间内透明地处理数十万个系列,同时具有高可用性。
最重要的是,它设法保持相对容易操作,占用空间非常小。毫无疑问,它是AWS Managed Prometheus Service 背后的动力。
日志
历史上,日志一直是一个痛点,尤其是在 MangaDex。事实上,它们在处理和存储方面的成本很高,而且其中大部分是完全无用的,永远不会被关注。我们在严格的限制下运营,因此将我们的一些宝贵资源奉献给他们并不是我们特别兴奋的事情。
然而,它们仍然是必不可少的,通过一些权衡和 Grafana 出色的Loki,我们能够每秒处理、存储和查询超过 7000 条日志行
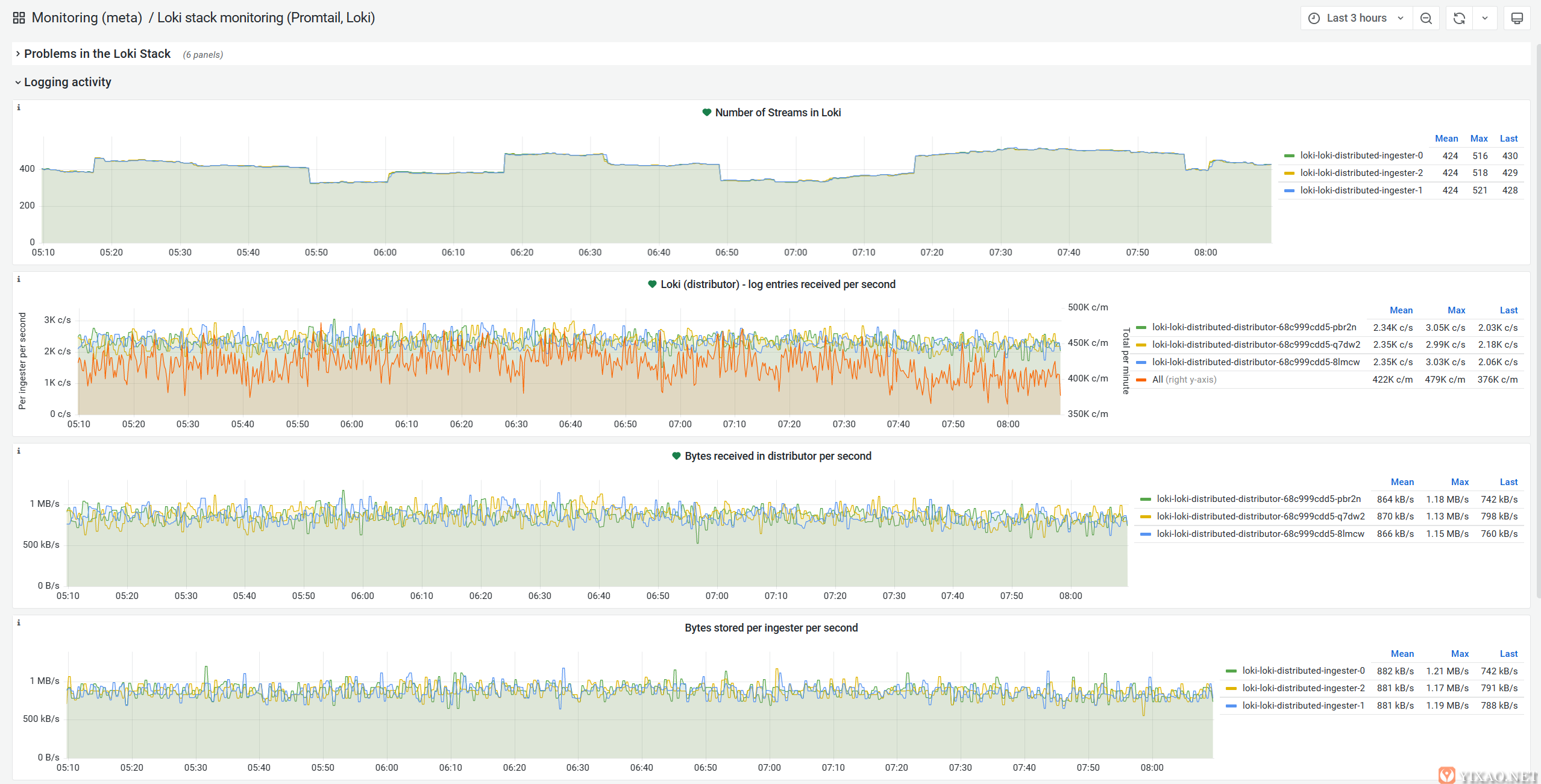
日志摄取指标
因为这可能是做出的第一个非常规堆栈选择之一,让我们将它与无处不在的Elastic Stack(又名 ELK 堆栈,或其基于Fluentd的“EFK”变体)进行比较,后者是日志集中化的黄金标准。也就是说,Elasticsearch 用于存储,Logstash 用于摄取,Kibana 用于搜索。
虽然 Elasticsearch 是一个令人难以置信的高效数据库,尤其是在全文搜索方面,但它带来了不小的资源成本。它必须构建适合复杂文本搜索的索引,这是资源和存储密集型的。但是,这允许它在很宽的时间范围内以及通过大量日志执行复杂的分析和搜索。
Loki 对这个问题采取了不同的方法。它基本上完全放弃了长期复杂的分析和索引,这有一些优点和缺点。
从好的方面来说,这意味着无需为大量索引分配空间,并且能够以高度压缩的方式存储日志。请注意,提高空间效率并不意味着日志仍然不会占用大量空间。出于这个原因,我们仍然将自己的日志保留时间限制在一周(使用 S3 对象生命周期策略很容易配置)
$ ceph df
POOLS:
POOL ID PGS STORED OBJECTS USED %USED MAX AVAIL
logs 23 128 804 GiB 706.84k 1.0 TiB 6.70 11 TiB
12345不好的一面是,这意味着它提供了更有限的功能集,并且本质上必须通过任何搜索进行暴力破解。当涉及到查询路径时,可以将其视为一种非常精细的 grep。
幸运的是,在其微服务部署中,它能够通过将搜索的时间范围划分为更小的部分并将其在其查询器实例中并行化,从而大大加快搜索操作的速度。
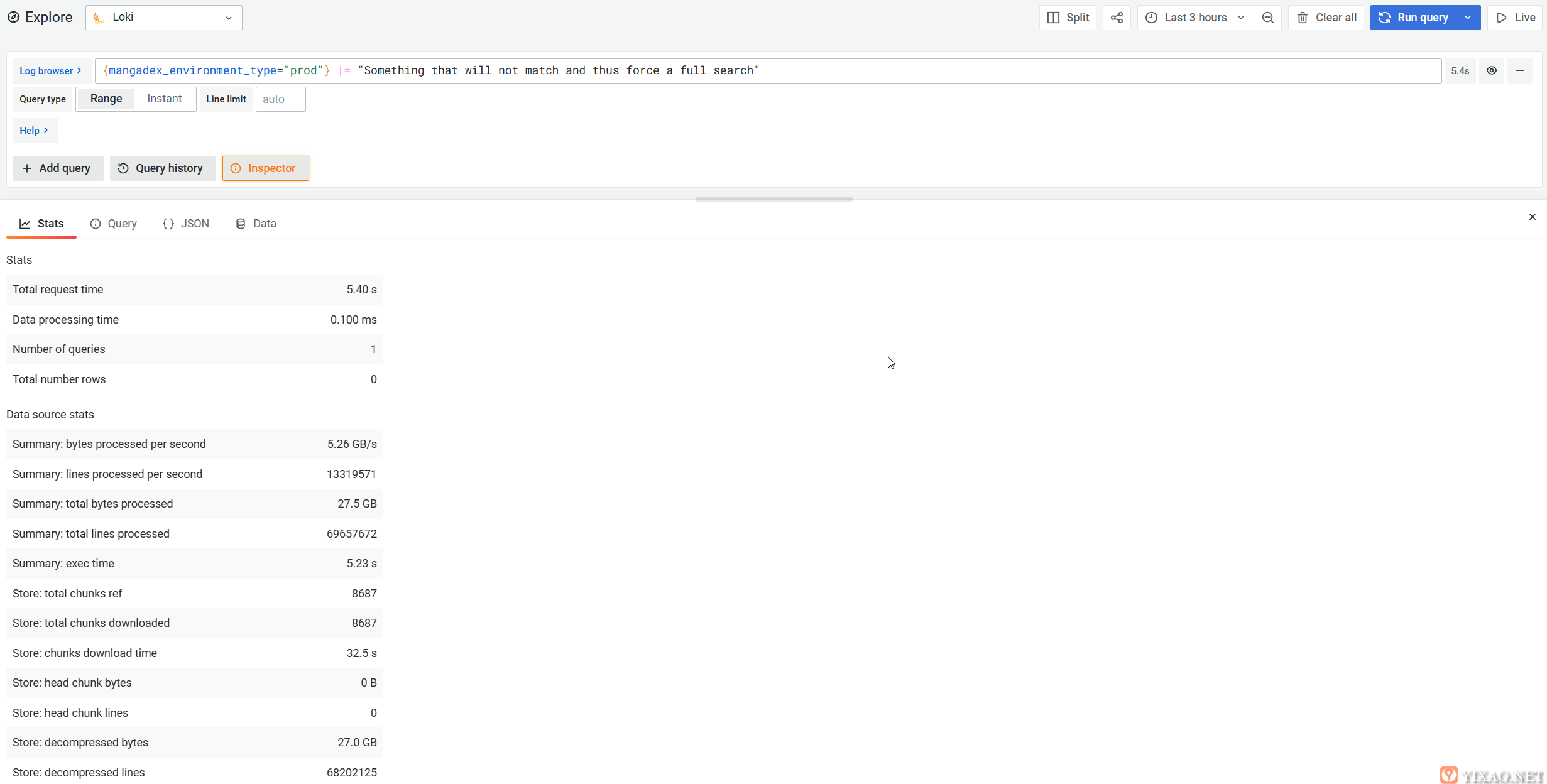
一个示例否定搜索显示 Loki 以略高于 5GB/s 的速度筛选日志
搜索时,值得庆幸的是,可以在查询中优化目标,这有助于避免扫描一些更庞大的流(即源和标签的组合),并最终生成更快的查询。
安全可靠
从安全的角度来看,该站点应该不受人为错误的影响。
需要明确的是,恶意的内部行为者极难防范,但我们确实采取措施来限制一个人可能造成的损害,方法是强制执行对内部服务的精细且有限的访问,并在发生以下情况时在场外保持严密保护的备份一个重大的妥协。
除此之外,我们唯一可以肯定的是,我们并非万无一失,从长远来看,偶尔的善意混乱是不可避免的。因此,我们需要确保此类事件的爆炸半径尽可能受到限制。
在实践中,这意味着我们:
- 运行所有应用程序的至少两个实例
- 在主机上 1 对 1 部署更新,以便在所有公共流量遇到故障实例之前发现问题
- 最后确保如果出现问题,可以快速回滚
从安全角度来看,我们还确保在私有网络上运行,并且任何面向用户的应用程序都保留在WAF 之后。为此,将流行的ModSecurity与OWASP 基金会的核心规则集一起使用,并密切监视或自动阻止可疑请求。

密切跟踪可疑/恶意请求
还遵守 OWASP 基金会的其他安全指南,分析/更新我们 CI 中的依赖项,并依赖主机和应用程序运行时级别的纵深防御机制。
最后,还密切监视对主机和内部服务的所有访问。
我们还跟踪 SSH 会话的来源和目标
一些限制
最安全、可观察、可靠和可扩展的基础设施是您实际上不必直接管理自己的基础设施。
如上图所示,有相当多的负载均衡器、网关和反向代理,这当然不会让事情变得简单。但是,有时您别无选择,而 MangaDex 尤其如此。
我们肯定会从使用主要云提供商之一(AWS、Azure 或 GCP)中受益匪浅,但遗憾的是,他们的成本结构非常适合那些实际上可以预期收入的公司,而不是像我们这样吝啬的客户5 …
为了好玩,这里有一个荒谬的保守估计,如果在 AWS 上运行,我们的账单会是什么样子……
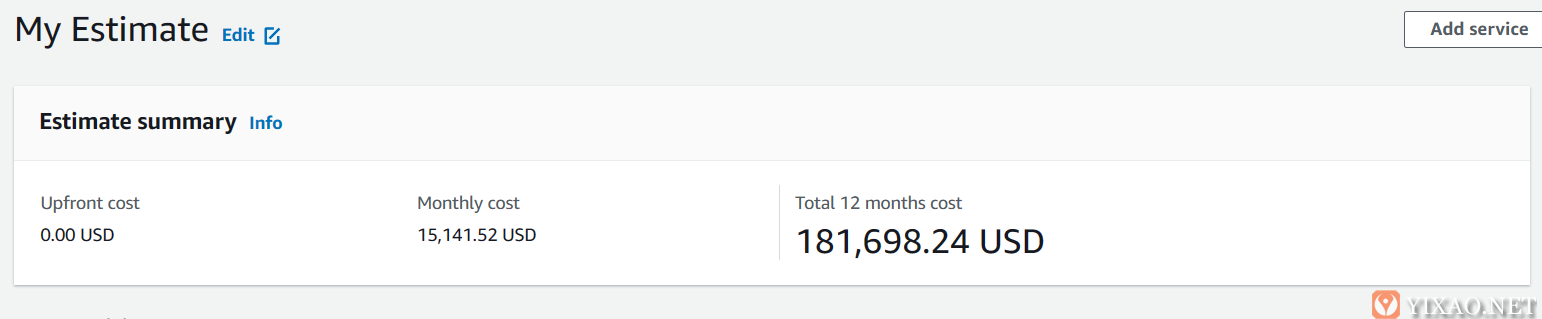
是的,忘记它
与此相关的一点是,我们过去一直依赖Cloudflare的出色服务,但遗憾的是,出于隐私原因,这不再是我们的选择。
总而言之,这意味着我们必须手工制作有关我们基础设施的一切。网络、数据库、安全等。我们还需要确保我们不受任何单一服务提供商的善意约束,以防他们突然决定改变主意与我们合作。
内容出处:,
声明:本网站所收集的部分公开资料来源于互联网,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,也不构成任何其他建议。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。文章链接:http://www.yixao.com/tech/28947.html
 微信扫一扫
微信扫一扫
 支付宝扫一扫
支付宝扫一扫
相关推荐
-
开源LiteOS 5.0发布啦,来瞅瞅物联网开发新“姿势”
2020,注定是不平凡的一年,这一年发生了太多事,疫情、贸易摩擦,给我们留下深刻记忆。年末岁尾,一切都在向好的方向发展,嫦娥五号携带月壤回家,新冠疫苗即将上市。经过攻城狮的日夜努力…
-
ABI企业级全能一站式数据分析平台
ABI是亿信华辰深耕商业智能领域十多年,在丰富的数据分析挖掘、报表处理等经验基础上,自主研发的一款融合了数据源适配、ETL数据处理、数据建模、数据分析、数据填报、工作流、门户、移动应用等核心功能而打造的全能型数据分析平台
-
2021年企业官方网站建设新趋势
公司官网是企业与用户沟通的桥梁,公司官网建设在网站建设的行业之中起着主导的地位,在众多的网站建设之中企业官方网站建设占得比重非常大,企业官方网站的目的不仅是营销还有展示企业文化,网…
-
OpenZFS 2.0.1 发布,支持 Linux 5.10
OpenZFS 2.0.1 发布了。OpenZFS(原名 ZFS)是 Linux、FreeBSD 与 macOS 平台上的文件系统,此前 11 月底发布的 OpenZFS 2.0….
-
如何申请免费顶级域名
1、浏览器打开https://my.freenom.com/官网 2、网站要在科学上网状态才可以打开(注意可以使用社交账号登陆;谷歌账号;Facebook都可以) 3、检查域名可用…
-
windows cmd命令汇总
目录: 文件与目录命令 网络相关命令 进程相关命令 平时我们操作较多的是linux,反而对windows 相关的命令不熟悉,下面是我总结的一些命令。有不清楚的,也可以在评论区告知我…
-
redis cluster搭建实践
一、Redis Cluster(Redis集群)简介 redis是一个开源的key value存储系统,受到了广大互联网公司的青睐。 redis集群采用P2P模式,是完全去中心化的…
-
flutter在windows和linux上运行IOS UI模拟器
我一般用的是device_preview这个插件,这个插件的闲置是只能做UI上的模拟,并没有真正的运行环境。 近似您的应用程序在另一台设备上的外观和性能。 插件名称 device_…
-
2023年科技圈的六大技术趋势
美国《福布斯》双周刊网站9月26日刊登题为《2023年技术大趋势 每个人现在都须做好准备》的一篇文章,作者是伯纳德·马尔。文章编译如下: 是的,对人工智能的大肆宣传已经有一段时间了…