淘宝搜索引擎至今已经迭代了多轮,搜索排序也已经从最开始的统计模型升级到机器学习模型;2010年前是没有标签概念的就是基础标签这些都没有,随着算力的增强,2010年后开始挖掘用户的基础标签,发展了三年到2013年才开始尝试使用大规模机器学习和实时化特征那个时候提出了个性化搜索;到了2015年推荐算法的方案才真正融合进搜索体系中,可以那么说2015年前淘宝搜索引擎都是在使用最开始的统计模型,统计模型最核心的就是关键词坑产权重。
但是大家有没有想过为什么2016-2017年的两年却是各种“黑搜”盛行的年份,又为什么到今天基本消失殆尽?
最根本的原因就是搜索排序从统计算法模型到机器学习模型的转变期。
说白一点,如果这个时候不收割就没有收割的机会了,因为统计模型即将退出历史舞台。
所以各路大神各显其通各种把统计模型算法中的影响元素放大,因为是统计算法不管是哪个点,点击率也好、坑产也罢,只要一个项做的很好搜索很容易起来。
那两年成了中小卖家狂欢盛宴,很多大神的烟火也很旺盛。
时至今日推荐算法第三代使用以后加上疫情的影响做个鲜明的对比,真的是感慨万千。
是淘宝真的没有流量了吗?是电商生意真的不好做了吗?还是大家的思维没有转变,还停留在2016-2017年的黑搜盛宴中不愿醒来?
2017年、2018年、2019年是淘宝推荐算法迭代最快的三年,每一年算法都升级都是不一样的,总体来说2019年9月份以前统计算法模型影响因素还很大的,2019年下半年开始第三代推荐算法以后,全面真意义的进入以机器学习模型为核心的推荐算法时代。
各路大神也不灵验了,加上百年疫情的影响,很多“大神”的遮羞布也就漏出来了。
基本以统计模型为主,搞培训的基本没有了声音、典型的就是坑产玩法。
如果你现在还能看到,基本可以判定他不是在做培训而是在做刷单,一定会推荐你用资源,而且资源多么的安全。
刷坑产递增真的没有效果了吗?也不是我前面文章就给大家提过方向:“不是不行了,只是不能从坑产的角度再思考,而是从改变竞争环境的角度去思考,用补单改变竞争环境,改变场、会有新天地,任何的手段都要服务于商业本质”。
正文
概述统计算法模型时代。
统计模型时代搜索引擎的排序是最原始的倒排思维,只要你类目不放错、关键词比较精准就可以拿到很大的流量,那时候产品少需求大,只要通过上下架的优化就可以让产品上首页。
话有说过来了2016年以前就没有坑产玩法吗?黑搜效果就不好吗?其实斐然哪个时候“坑产”是最核心机密,大家都闷声发大财谁来教你啊,哪个时候教你的最多就是类目优化,关键词优化,几乎所有的优化都围绕着关键词,电商老人回忆一下你哪个时候是不是就是得关键词者得天下。
有谁告诉你玩坑产,关键词找好了生意也就来了。哪个时候就是懂坑产也没人给你刷啊,大规模补单也就出现在黑搜盛行的时期。
为什么说得关键词者得天下呢?
搜索关键词是用户当前意图最直观表达,也是用户表达意图的最直接的方式。
来搜索的用户购物意图最强、成交意愿也最强就是现在搜索也是转化率最高的流量来源。
统计时代关键词背后直接挂靠的就是类目商品,只需把类目和关键词分词做好就行了,哪个时代出现最多的黑马一般都是类目机会,关键词机会,黑科技机会。
最根本的还是商业本质,哪个时候产品少需求大,很多现在的类目都没有,自己都创找一个类目出来,现在想想是什么概念。
记得哪个时候类目哪怕错放,搜索都可以来,只要你商品的点击反馈好就是放错类目都不怎么影响,现在你试试?
对于搜索类目是搜索的基石。
哪个时候就可以颠覆,背后就是商业逻辑,用户行为数据好就行。
但是无论怎么发展搜索永远离不开关键词,就如上述说的关键词是用户表达意图的最直接的方式,就是现在消费者的搜索行为或者购买行为发生根本性改变。
搜索依然是根据消费者身上的行为数据及关键词来判断需求,这就是机器学习模型时代。
机器学习模型时代–推荐搜索算法。
现在的商品体量以及消费者购物行为的丰富性,统计算法已经不能满足搜索的本质要求。
所以现在搜索引擎开始发展深度学习模型更精细的建模–推荐搜索算法,搜索排序更加智能化。
在此重点论述推荐搜索算法,
前面有提到2017、2018、2019、是推荐搜索算法真正意义发展的三年,三年三个系统版本一年一换,以至于很多电商人摸不清头脑了。
推荐搜索算法和统计算法模型最大的不同,在于“Query”的处理能力和算法上有了召回机制
简单表示推荐算法的流程步骤:
一:会对搜索关键词进行分词、改写的处理进行类目预判
二:会根据用户信息也就是用户之前的行为数据记录及预估的性别、年龄、购买力、店铺偏好、品牌偏好、实时行为等信息进行存档
三:会根据搜索用户信息建立好倒排的搜索引擎依据搜索词,类目预测信息进行召回,粗排,精排最终将把权重分数最高的TOP N的商品搜索排序呈现此搜索用户
依据分词、类目召回,根据用户行为数据信息进行个性化精准排序是推荐搜索算法的最大特点。
也就是说在第一关召回阶段基本和统计模型时代的优化渠道是一样的,核心是标题分词和类目,现在最大的不同就是会依据用户信息进行推荐精排,这就是标签和精准人群标签画像优化的最根本意义。
现在为什么一直谈标签,谈人群标签画像了吗?“入池”其实就是在匹配真实购买消费者用户信息,通过直通车测试判断确定人群也是通过性别、年龄、购买力,搜索偏好来优化匹配真实购买消费者。
召回机制:
通过构建子单元索引的方式来加速对商品的检索,这样就不用遍历平台上亿级所有商品,这个索引就是搜索引擎中的倒排索引,利用倒排索引对商品进行初筛的过程就是召回阶段。
在这个阶段,不会进行复杂的计算,主要根据当前的搜索条件进行商品候选集的快速圈定。
在此之后,再进行粗排和精排,计算的复杂程度越来越高,计算的商品集合逐渐减少,最后完成整体的排序过程。
主要召回路径分为:
一:词召回
二:向量召回
这些都是商业机密了不便阐述,有兴趣可以学习一下我们线上会员课程“标签叠加玩法6.0”就是基于词和向量召回的底层逻辑应用于实战落地的课程。
下一个阶段就进入了粗排,粗排又是受哪些因素影响:
粗排作为召回之后的第一道门槛,为了用户体验希望用一个耗时低的模型对商品进行快速排序和筛选,第一关就要过滤到大部分不适合这次搜索词请求的商品。
要想实现这个目的就必须先搞清楚影响粗排得分因子
一:类目匹配得分及文本匹配得分,
二:商品信息质量(商品发布时间、商品的级别、商家级别)
三:商品组合分数
点击得分
交易得分
卖家服务商业分数
在粗排框架下,系统粗排算法会根据商品的类目预测分数对每个商品进行类目分档,位于不同档位的商品会得到不同的类目分数,与搜索关键词的相关性越高,那么该类目下的商品得分就会越高,同样文本匹配分数及商品信息质量,商品组合分数做了相应的分档处理进行优化,这就是粗排过程中的影响因素及优化流程。
最后就是精排,搜索排序的主要目标是高相关性、高个性化精准性。
每个用户的喜好不同,系统会根据每个用户的Query结合用户信息进行召回。然后通过粗排之后,商品数量从万级别下降到千级别。
千级别的商品经过精排后会直接展示给用户,搜索过程中商品集合的思维及具体变化如下图
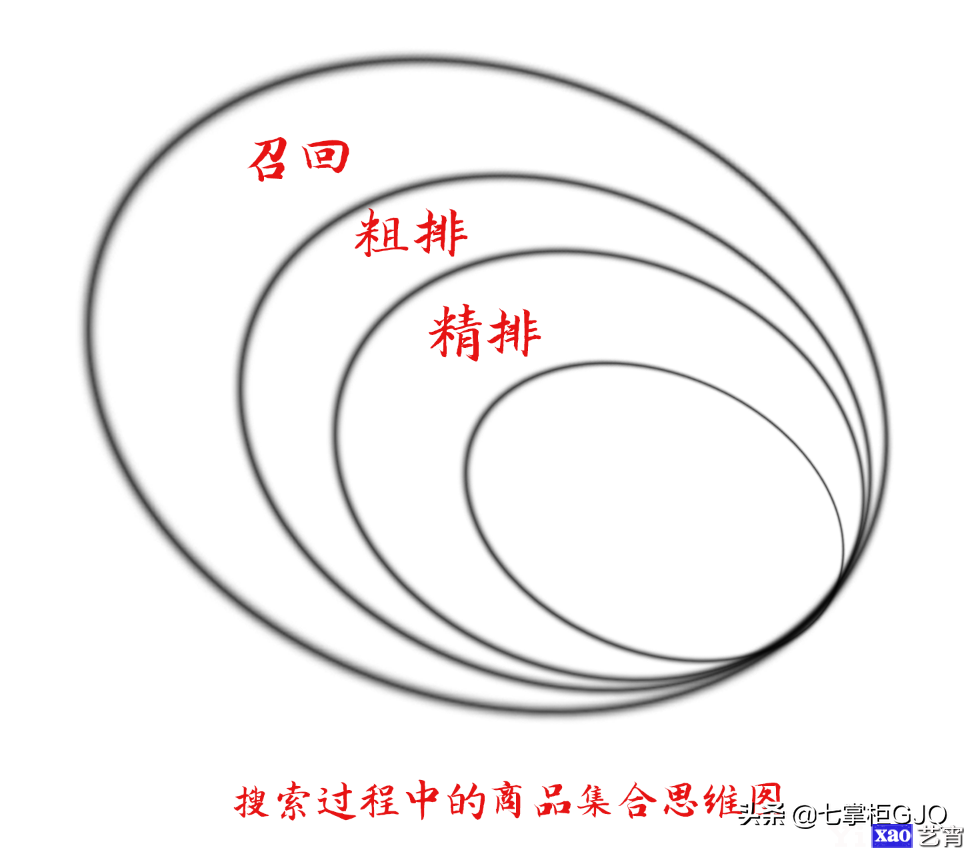

前面的召回、粗排主要是解决主题相关性,通过主题相关性的限制,先缩小商品集合和我们线上会员课程标签叠加玩法中的核心思维“聚焦”异曲同工。
在精排阶段系才是真正系统推荐算法发挥真正威力的时候,应该基于用户行为反馈快速进行机器学习建模,判断用户的真实性,精准性和可持续可控制性。
这里插一句为什么现在所谓的玩法或者黑科技都是昙花一现,核心就是系统算法模型—机器学习模型,系统分析出用户有问题,不精准,不稳定,可维持性差就会进行快速调整。
也就是说你即使发现漏洞或者研究出快速有效的方法,系统也会根据你精排阶段的用户人群行为进行快速的分析学习建模,发现模型有问题你的玩法也就完蛋了。
你猜猜机器学习建模的速度有多快?
想玩黑的趁早死了这条心吧。
现在利用的搜索排序模型主要是:
CTR模型和CVR模型,具体模型太复杂也没必要深入,但是你要知道影响这两个模型最根本因素就是用户行为数据。
真的假不了,假的也真不了;算法模型越来越智能化,算法越来越强大只有回归到商业的本质才能真正解决算法模型背后真正想解决的问题,算法基于商业逻辑。
2021年搜索会向哪个方向变化:
2020年对电商人及阿里都是不平凡的一年。2020也是阿里从神坛被拉下来的元年,现在对阿里是各种黑。
基于中小卖家的流失确实是阿里必须正面面对的现实。
如何让中小卖家回流或者留在平台上,搜索应该怎么做?
搜索肯定会基于三方考虑,买家,卖家和平台自身,现在市面上又开始鼓吹坑产搜索逻辑,坑产的妖风又要起,基于推荐搜索算法逻辑来谈一下这个问题。
为什么坑产思维,是打不死的小强,每次“危机”都会跳出来。
以统计模型为主的坑产时代是从淘宝建立2003到2015年一直在用的搜索算法模型长达13年之久。
同时是淘宝和中国网民红利的野蛮增长时期,统计算法模型让太多的电商人赚到钱了。
加之十年奴役思维已经习惯了、在电商圈你说坑产玩法一定有人信,讲其他未必被人认同。这也是为什么我们夹着尾巴发展的原因,时间真的可以证明一切、无需多言,做好自己。
习惯性思维加上特殊时期的赚钱蝴蝶效应,让大多数电商人还活在历史的旧梦里。
确切的说,统计算法模型真正的废除是在2019下半年。
有同学会说坑产永远有效,我也这样认为。
永远有效的是爆款模型坑产权重驱动和统计算法模型中的“坑产”排序不是一回事。
爆款模型中的坑产因素是永远有效的,这个永远不变。
但是怎么有效的加上这个爆款模型坑产权重,不是你去模仿下购物意图去打个标、然后成交那么简单的事情。
坑产玩法在2021年肯定不行,淘宝肯定不会把现在的算法系统,换成15年前的。
基于三方利益:
买家的体验
卖家的收益
平台的发展
搜索肯定还是会向高精准性和高可控性发展;以标签为核心的用户标签画像依然是影响流量精准度的根本因素这一点不会变。
必须要从标签的角度去思考和优化种子人群画像,
通过种子人群画像向相似人群扩展再到叶子类目人群,再到行业偏好人群最后到关联类目人群进行扩展,这也是流量放大的流程通道。
基于推荐搜索算法逻辑:
在精排阶段应该算法更强大精准度更高,转化率应该会有所提高,持续性稳定性应该更强。
基于中小卖家流逝的现状,做精排阶段的优化不是中小卖家能简单触达到的。
如果推荐算法要放水从搜索排序阶段中会出现在哪个阶段?
个人判断
一是召回阶段
二是粗排阶段
上述有提到召回阶段的算法简单覆盖商品是万级,排序规则也比较简单,如果针对中小卖家在召回阶段提高精准度就尤为重要。
如果在这个万级的商品库中比如上下架权重提高让中小卖家都有机会上首页,从子单元索引召回中找机会。
或者基于中小卖家新品及中小卖家的店铺层级进行针对搜索推荐特别优先权让中小卖家的新品在低销量状态下进行展现,一个锦囊算法就可以实现。
让中小卖家都有上搜索首页的机会,先不调用用户信息就直接给打开首页展现权这可能是对中小卖家最大的支持。
根据召回阶段的用户行为数据在粗排阶段在占比例融入“用户信息”也就是标签影响。
在初始召回阶段,就看类目和分词权重就看商家的主图“场景”反应的背后人群反馈,再以系统加以引导,给中小卖家真正可借鉴的流量方向和成交方向。
谁疯狂刷单就直接关小黑屋,懂刷单优化竞争场景,从优化人群的角度除外,适当放宽处罚。
通过召回阶段,得到的用户信息去影响粗排结果。
这个阶段用户信息权重占比也不能太大,不能让流量卡的太死。
说白了就看在每个搜索排序阶段“用户信息”也就是用户标签对搜索的影响权重多大的问题。
这个方向我个人观点是极有可能的。
上述是我对搜索变化的一些判断,并不做参考。
如果你是搜索部门负责人,你会怎么思考这个问题?
内容出处:,
声明:本网站所收集的部分公开资料来源于互联网,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,也不构成任何其他建议。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。文章链接:http://www.yixao.com/seo/18582.html
 微信扫一扫
微信扫一扫
 支付宝扫一扫
支付宝扫一扫
相关推荐
-
百度竞价无线凤巢新推出CPA模式!无效果,不计费!
继今日头条首推CPA和CPV模式之后,百度SEM紧跟其后,无线凤巢也推出了CPA计费模式。 那么,什么是CPA呢? 我们通俗一点,举个例子: 你出差,住酒店 1、傍晚住酒店,想看看…
-
百度免费关键词优化的SEOer注意了,百度对URL有要求
对于网站的URL设计,虽然很少有人问到小编,但是小编却见过了各种各样五花八门的URL,现在,小编和大家聊聊什么是友好的URL设计 1、在搭建网站结构、制作URL时,尽量避开非主流设…
-
网络推广引流,被动流量,永远有效的方法
凡人往往只看重眼前一两年的收获,却忽略了未来十年所能获得的成就。 网络赚钱,我们只要比别人看的稍远一点,就能超越多数人。 我做事情更看重后端,也就是滚雪球效应,前期累点,后期越做越…
-
引流心法:垂直化搜索的干预技巧
一)神迹 在古代,如何衡量一个人博学? 学富五车,看过很多书。 博文强记,记忆力强悍。 这天下何其广袤,五车书之外又该如何?记忆力再强又能记多少? 活人不能被尿憋死,不懂可以问,问…
-
5个主流搜索引擎信息流广告效果和投放体验
做了好几年的广告投放,很少对5个搜索引擎广告效果做一个总结和梳理。它们分别是百度竞价、360竞价、搜狗竞价、神马搜索、字节巨量广告。 本篇谈下我的一些个人体验。 1:百度 我第一次…
-
网站SEO搜索引擎优化50个技巧
做个人博客大多数是有情怀缘故,该博客是第三版 是PHP语 言捣扯的-情怀不能当饭吃,做着做着感觉自己看那没意思了,我要让更多人能看到我的分享。于是就搞SEO优化到不可收拾的地步&#…
-
H5游戏如何出海获取流量?
2020年11月24日-27日,谷歌年度H5游戏线上课程正式开课,针对H5游戏品类系统性的作出梳理。 在11月25日的课程中,Google大中华区代理商管理部高级经理Sophia …
-
网站SEO长尾关键词优化技巧
在网站SEO优化上,优化比较成功的网站,根据SEO界前辈的经验结论,网站的总流量主要来源于长尾关键词,占网站总流量的80%。长尾关键词主要分布在网站的文章页,其次就是栏目页titl…
-
微信公众号通过淘宝、抖音都能为之引流推广
客户点一下超级引流连接就可以自动一键跳转到微信,并看到企业二维码,客户只需要长按二维码就能快速添加企业员工微信或企业微信群,或关注微信公众平台为公众号吸粉等。
-
SEO提升流量过程中内容增减有什么影响?
当我们在做SEO的时候,对于企业网站而言,总是会遇到这样的事情,网站权重看着不错,也有上百个关键词,可对于一些运营者来讲,总是不满足,每天都在思考,新增页面,去做更多的关键词排名,…